 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBOS-RL: Feedback-Driven Bi-Objective Synergistic Reinforcement Learning
May 18, 2026Reinforcement learning has become a cornerstone for aligning and unlocking the reasoning capabilities of large-scale models. At its core, the training loop of GRPO and its variants alternates between rollout sampling and policy update. Unlike supervised learning, where each gradient step is anchored to an explicit ground-truth target, the optimal gradient direction for updating model parameters in this setting is not known a priori; the high-quality rollouts drawn during the sampling stage therefore act as the implicit "teacher" that guides every parameter update. However, GRPO adopt a simple sampling scheme that conditions all rollouts on the same original prompt. When a task lies beyond the policy model's current capability, this sampling scheme rarely yields a high-quality rollout, leaving the policy model without a meaningful gradient direction when updating its parameters, which causes training to stall. To address this issue, we propose FBOS-RL, a Feedback-Driven Bi-Objective Synergistic reinforcement learning framework. Specifically, we let the model perform Feedback-Guided Exploration Enhancement based on the feedback provided by the environment, and on top of this we design two mutually reinforcing training objectives: Exploitation-oriented Policy Alignment(EPA) and Exploration-oriented Capability Cultivation(ECC). Extensive experiments demonstrate that EPA and ECC can mutually reinforce each other, forming a positive flywheel effect that significantly improves both the training efficiency and the final performance ceiling of reinforcement learning. Specifically, under an identical number of rollouts, FBOS-RL learns substantially faster than GRPO and feedback-based baselines and ultimately attains a higher performance ceiling, while exhibiting higher policy entropy and lower gradient norms throughout training.
Recycling Failures: Salvaging Exploration in RLVR via Fine-Grained Off-Policy Guidance
Feb 27, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the complex reasoning capabilities of Large Reasoning Models. However, standard outcome-based supervision suffers from a critical limitation that penalizes trajectories that are largely correct but fail due to several missteps as heavily as completely erroneous ones. This coarse feedback signal causes the model to discard valuable largely correct rollouts, leading to a degradation in rollout diversity that prematurely narrows the exploration space. Process Reward Models have demonstrated efficacy in providing reliable step-wise verification for test-time scaling, naively integrating these signals into RLVR as dense rewards proves ineffective.Prior methods attempt to introduce off-policy guided whole-trajectory replacement that often outside the policy model's distribution, but still fail to utilize the largely correct rollouts generated by the model itself and thus do not effectively mitigate the narrowing of the exploration space. To address these issues, we propose SCOPE (Step-wise Correction for On-Policy Exploration), a novel framework that utilizes Process Reward Models to pinpoint the first erroneous step in suboptimal rollouts and applies fine-grained, step-wise off-policy rectification. By applying precise refinement on partially correct rollout, our method effectively salvages partially correct trajectories and increases diversity score by 13.5%, thereby sustaining a broad exploration space. Extensive experiments demonstrate that our approach establishes new state-of-the-art results, achieving an average accuracy of 46.6% on math reasoning and exhibiting robust generalization with 53.4% accuracy on out-of-distribution reasoning tasks.
IMAGINE: Integrating Multi-Agent System into One Model for Complex Reasoning and Planning
Oct 16, 2025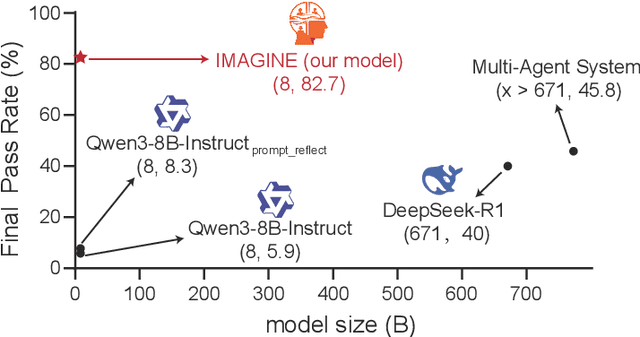
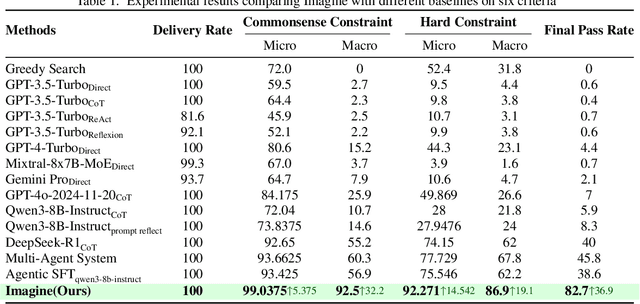
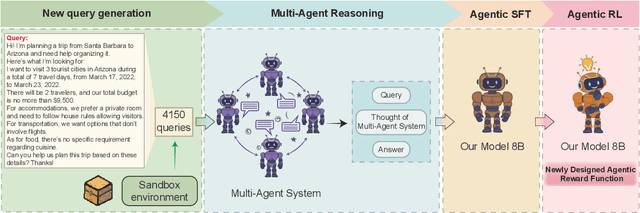

Although large language models (LLMs) have made significant strides across various tasks, they still face significant challenges in complex reasoning and planning. For example, even with carefully designed prompts and prior information explicitly provided, GPT-4o achieves only a 7% Final Pass Rate on the TravelPlanner dataset in the sole-planning mode. Similarly, even in the thinking mode, Qwen3-8B-Instruct and DeepSeek-R1-671B, only achieve Final Pass Rates of 5.9% and 40%, respectively. Although well-organized Multi-Agent Systems (MAS) can offer improved collective reasoning, they often suffer from high reasoning costs due to multi-round internal interactions, long per-response latency, and difficulties in end-to-end training. To address these challenges, we propose a general and scalable framework called IMAGINE, short for Integrating Multi-Agent System into One Model. This framework not only integrates the reasoning and planning capabilities of MAS into a single, compact model, but also significantly surpass the capabilities of the MAS through a simple end-to-end training. Through this pipeline, a single small-scale model is not only able to acquire the structured reasoning and planning capabilities of a well-organized MAS but can also significantly outperform it. Experimental results demonstrate that, when using Qwen3-8B-Instruct as the base model and training it with our method, the model achieves an 82.7% Final Pass Rate on the TravelPlanner benchmark, far exceeding the 40% of DeepSeek-R1-671B, while maintaining a much smaller model size.